Re: chapoly acceleration hardware [Was: Re: [RFC PATCH 00/18] crypto: wireguard using the existing crypto API]
From: Dave Taht <hidden>
Date: 2019-09-26 23:14:01
Also in:
linux-crypto, netdev
On Thu, Sep 26, 2019 at 6:52 AM Pascal Van Leeuwen [off-list ref] wrote:
quoted
-----Original Message----- From: Jason A. Donenfeld <Jason@zx2c4.com> Sent: Thursday, September 26, 2019 1:07 PM To: Pascal Van Leeuwen <redacted> Cc: Ard Biesheuvel <redacted>; Linux Crypto Mailing List <linux- crypto@vger.kernel.org>; linux-arm-kernel [off-list ref]; Herbert Xu [off-list ref]; David Miller [off-list ref]; Greg KH [off-list ref]; Linus Torvalds [off-list ref]; Samuel Neves [off-list ref]; Dan Carpenter [off-list ref]; Arnd Bergmann [off-list ref]; Eric Biggers [off-list ref]; Andy Lutomirski [off-list ref]; Will Deacon [off-list ref]; Marc Zyngier [off-list ref]; Catalin Marinas [off-list ref]; Willy Tarreau [off-list ref]; Netdev [off-list ref]; Toke Høiland-Jørgensen [off-list ref]; Dave Taht [off-list ref] Subject: chapoly acceleration hardware [Was: Re: [RFC PATCH 00/18] crypto: wireguard using the existing crypto API] [CC +willy, toke, dave, netdev] Hi Pascal On Thu, Sep 26, 2019 at 12:19 PM Pascal Van Leeuwen [off-list ref] wrote:quoted
Actually, that assumption is factually wrong. I don't know if anything is *publicly* available, but I can assure you the silicon is running in labs already. And something will be publicly available early next year at the latest. Which could nicely coincide with having Wireguard support in the kernel (which I would also like to see happen BTW) ... Not "at some point". It will. Very soon. Maybe not in consumer or server CPUs, but definitely in the embedded (networking) space. And it *will* be much faster than the embedded CPU next to it, so it will be worth using it for something like bulk packet encryption.Super! I was wondering if you could speak a bit more about the interface. My biggest questions surround latency. Will it be synchronous or asynchronous?The hardware being external to the CPU and running in parallel with it, obviously asynchronous.quoted
If the latter, why?Because, as you probably already guessed, the round-trip latency is way longer than the actual processing time, at least for small packets. Partly because the only way to communicate between the CPU and the HW accelerator (whether that is crypto, a GPU, a NIC, etc.) that doesn't keep the CPU busy moving data is through memory, with the HW doing DMA. And, as any programmer should now, round trip times to memory are huge relative to the processing speed. And partly because these accelerators are very similar to CPU's in terms of architecture, doing pipelined processing and having multiple of such pipelines in parallel. Except that these pipelines are not working on low-level instructions but on full packets/blocks. So they need to have many packets in flight to keep those pipelines fully occupied. And packets need to move through the various pipeline stages, so they incur the time needed to process them multiple times. (just like e.g. a multiply instruction with a throughput of 1 per cycle actually may need 4 or more cycles to actually provide its result) Could you do that from a synchronous interface? In theory, probably, if you would spawn a new thread for every new packet arriving and rely on the scheduler to preempt the waiting threads. But you'd need as many threads as the HW accelerator can have packets in flight, while an async would need only 2 threads: one to handle the input to the accelerator and one to handle the output (or at most one thread per CPU, if you want to divide the workload) Such a many-thread approach seems very inefficient to me.quoted
What will its latencies be?Depends very much on the specific integration scenario (i.e. bus speed, bus hierarchy, cache hierarchy, memory speed, etc.) but on the order of a few thousand CPU clocks is not unheard of. Which is an eternity for the CPU, but still only a few uSec in human time. Not a problem unless you're a high-frequency trader and every ns counts ... It's not like the CPU would process those packets in zero time.quoted
How deep will its buffers be?That of course depends on the specific accelerator implementation, but possibly dozens of small packets in our case, as you'd need at least width x depth packets in there to keep the pipes busy. Just like a modern CPU needs hundreds of instructions in flight to keep all its resources busy.quoted
The reason I ask is that a lot of crypto acceleration hardware of the past has been fast and having very deep buffers, but at great expense of latency.Define "great expense". Everything is relative. The latency is very high compared to per-packet processing time but at the same time it's only on the order of a few uSec. Which may not even be significant on the total time it takes for the packet to travel from input MAC to output MAC, considering the CPU will still need to parse and classify it and do pre- and postprocessing on it.quoted
In the networking context, keeping latency low is pretty important.I've been doing this for IPsec for nearly 20 years now and I've never heard anyone complain about our latency, so it must be OK.
Well, it depends on where your bottlenecks are. On low-end hardware you can and do tend to bottleneck on the crypto step, and with uncontrolled, non-fq'd non-aqm'd buffering you get results like this: http://blog.cerowrt.org/post/wireguard/ so in terms of "threads" I would prefer to think of flows entering the tunnel and attempting to multiplex them as best as possible across the crypto hard/software so that minimal in-hw latencies are experienced for most packets and that the coupled queue length does not grow out of control, Adding fq_codel's hashing algo and queuing to ipsec as was done in commit: 264b87fa617e758966108db48db220571ff3d60e to leverage the inner hash... Had some nice results: before: http://www.taht.net/~d/ipsec_fq_codel/oldqos.png (100ms spikes) After: http://www.taht.net/~d/ipsec_fq_codel/newqos.png (2ms spikes) I'd love to see more vpn vendors using the rrul test or something even nastier to evaluate their results, rather than dragstrip bulk throughput tests, steering multiple flows over multiple cores.
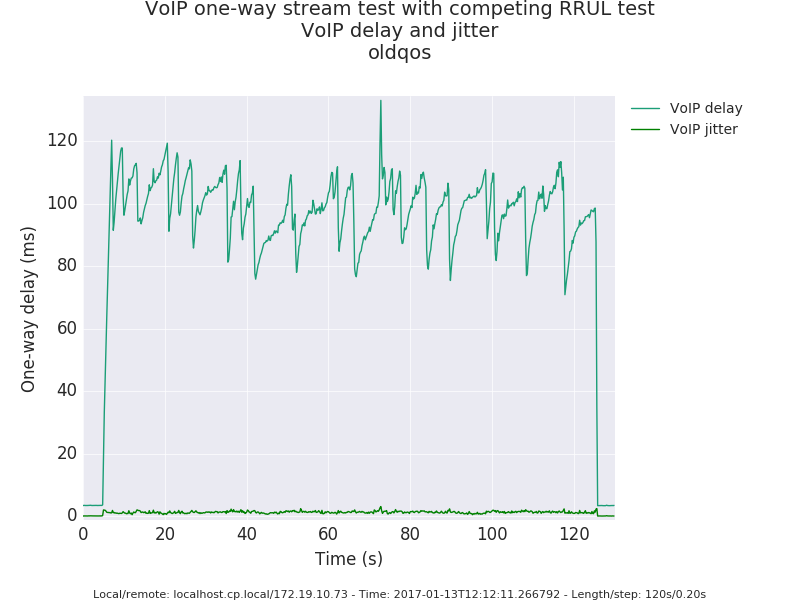{kind=link}
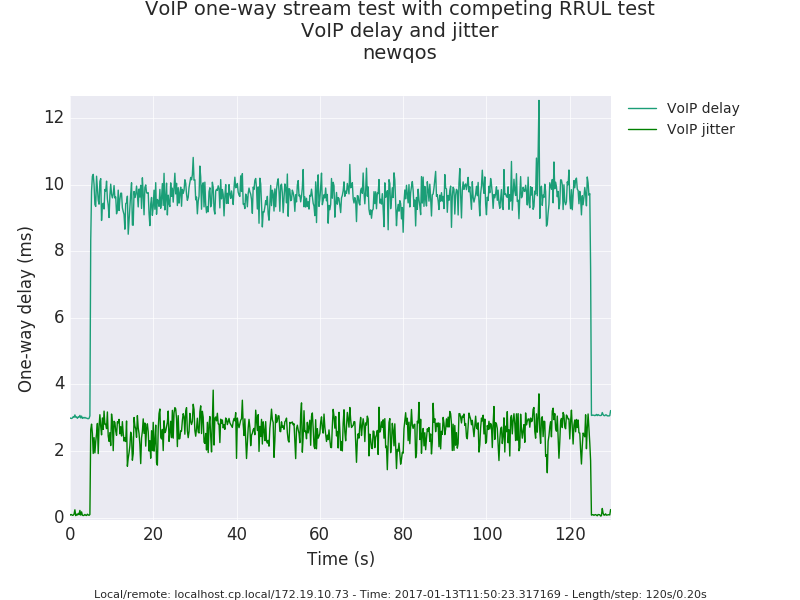{kind=link}
We're also doing (fully inline, no CPU involved) MACsec cores, which operate at layer 2 and I know it's a concern there for very specific use cases (high frequency trading, precision time protocol, ...). For "normal" VPN's though, a few uSec more or less should be a non-issue.
Measured buffering is typically 1000 packets in userspace vpns. If you can put data in, faster than you can get it out, well....
quoted
Already WireGuard is multi-threaded which isn't super great all the time for latency (improvements are a work in progress). If you're involved with the design of the hardware, perhaps this is something you can help ensure winds up working well? For example, AES-NI is straightforward and good, but Intel can do that because they are the CPU. It sounds like your silicon will be adjacent. How do you envision this working in a low latency environment?Depends on how low low-latency is. If you really need minimal latency, you need an inline implementation. Which we can also provide, BTW :-) Regards, Pascal van Leeuwen Silicon IP Architect, Multi-Protocol Engines @ Verimatrix www.insidesecure.com
-- Dave Täht CTO, TekLibre, LLC http://www.teklibre.com Tel: 1-831-205-9740 _______________________________________________ linux-arm-kernel mailing list linux-arm-kernel@lists.infradead.org http://lists.infradead.org/mailman/listinfo/linux-arm-kernel